官网地址: https://varytoy.github.io/
在当今快速发展的科技时代,视觉语言模型给人工智能(AI)领域带来了巨大变革。其中,Vary-toy作为一款新兴工具,正逐步展示它的潜力和多样性。由MEGVII Technology、北京大学和华中科技大学的研究团队共同开发,Vary-toy旨在有效解决大型视觉语言模型在训练与部署中所面临的挑战。本文将深入探讨Vary-toy的功能、应用及其使用价值。
Vary-toy的基本功能
Vary-toy具备强大且多样化的功能,使其在多个领域都有广泛的应用。以下是Vary-toy的核心功能:
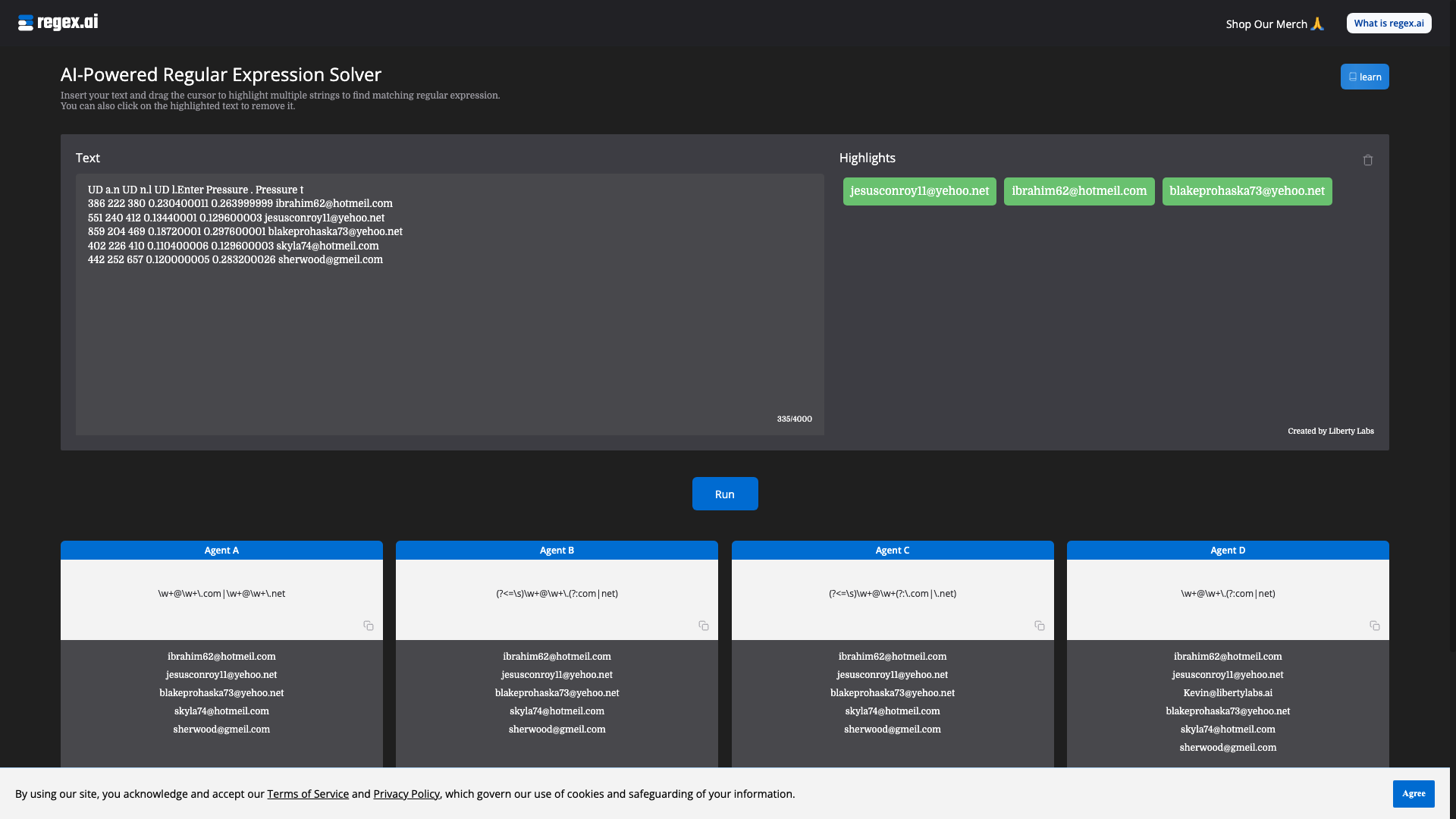
- 文档级光学字符识别(OCR):Vary-toy能够精准识别并提取图片中的文字信息,支持多种文件格式,包括PDF等。
- 图像描述:这项功能使得用户能够上传图像,Vary-toy将自动生成图像的简要描述,帮助用户快速了解图像内容。
- 视觉问答:用户可以依据图像内容提问,Vary-toy能够理解问题并给出相关的答案,增强人机互动的趣味性。
- 对象检测:Vary-toy能够在图像中识别并标记出不同的对象,为后续处理提供支持。
- 图像到文本转换:该功能使得用户能够将图像中的信息转化为可编辑的文本,大大提高了数据的使用价值。
- 多模态对话:Vary-toy支持用户与其进行自然的对话,不论是图像内容还是日常话题,这使得对话更加智能和人性化。
如何有效使用Vary-toy
Vary-toy因其小巧的体积而著称,适合在消费级GPU上进行训练和部署。这一特性让它成为开发者和研究人员的理想选择。使用Vary-toy的步骤相对简单:
1. **注册并登录**:用户首先需要注册Vary-toy账户,以获取其使用权限。
2. **上传数据**:用户可以上传需要分析的图像或文档,支持多种格式的文件上传。
3. **选择功能**:根据需求,用户可以选择OCR、图像描述、视觉问答等不同功能。
4. **获取结果**:Vary-toy将自动处理用户提交的数据,并输出相应的结果。
Vary-toy的这一系列功能为用户提供了便捷的体验,使用户能够更快速地获取所需信息。
Vary-toy的实际应用案例
Vary-toy在实际应用中展现出了广阔的前景。以下是几个具体的应用案例:
1. **图像识别**:用户上传一张包含多种物体的图片,Vary-toy能够迅速识别出每个物体并为其打上标签,帮助用户更好地理解图像内容。
2. **PDF图像OCR**:用户将一份含有图像的PDF文件上传后,Vary-toy可以提取图中文字,并将其转化为Markdown格式,方便用户后续编辑和使用。
3. **日常对话**:在一次日常交流中,用户与Vary-toy进行对话,讨论了图像中的具体内容,Vary-toy不仅理解了话题,还能继续展开讨论,展现出其强大的自然语言处理能力。
这些应用不仅提高了工作效率,而且提升了用户的整体体验,使其能够在复杂的工作中减少人力资源的投入。
Vary-toy的未来展望
随着技术的不断发展,Vary-toy将继续演进,具备更强大的功能和更广泛的应用场景。展望未来,Vary-toy可能会实现以下几方面的突破:
1. **更加精准的模型训练**:通过引入更多的数据集和训练机制,Vary-toy将提升其在准确性和效率上的表现。
2. **跨域应用**:Vary-toy的多模态对话功能可运用到更多的行业场景,比如医疗、教育等领域,进一步拓宽其应用边界。
3. **用户自定义功能**:未来可能会为用户提供更高的自定义权限,让用户可以根据自身需求调整模型,提高使用的灵活性。
总之,Vary-toy的出现不仅是在技术领域的一次创新,更是在实际应用中提升效率的重要工具。通过不断迭代与升级,对于任何需要强化视觉语言理解的用户,Vary-toy都将是一个理想的选择。
基于其强大的功能与便捷的使用体验,Vary-toy毫无疑问会成为推动AI应用发展的重要力量。希望越来越多的用户能够通过这款工具,享受到技术带来的便捷与高效。